Generative AI is INCREDIBLY bad at mathmatical/logical reasoning. This is well known, and very much not surprising.
That’s actually one of the milestones on the way to general artificial intelligence. The ability to reason about logic & math is a huge increase in AI capability.
The bigger issue is abstract reasoning that necessitates nonlinear representations - things like Sodoku, where exploring a solution requires updating the conditions and pursuing multiple paths to a solution. This can be achieved with multiple calls, but doing it in a single process is currently a fool’s errand and likely will be until a shift to future architectures.
The linked research is about LLMs. The opening of the abstract of the paper:
In recent years, large language models have greatly improved in their ability to perform complex multi-step reasoning. However, even state-of-the-art models still regularly produce logical mistakes. To train more reliable models, we can turn either to outcome supervision, which provides feedback for a final result, or process supervision, which provides feedback for each intermediate reasoning step. Given the importance of training reliable models, and given the high cost of human feedback, it is important to carefully compare the both methods. Recent work has already begun this comparison, but many questions still remain. We conduct our own investigation, finding that process supervision significantly outperforms outcome supervision for training models to solve problems from the challenging MATH dataset. Our process-supervised model solves 78% of problems from a representative subset of the MATH test set. Additionally, we show that active learning significantly improves the efficacy of process supervision.
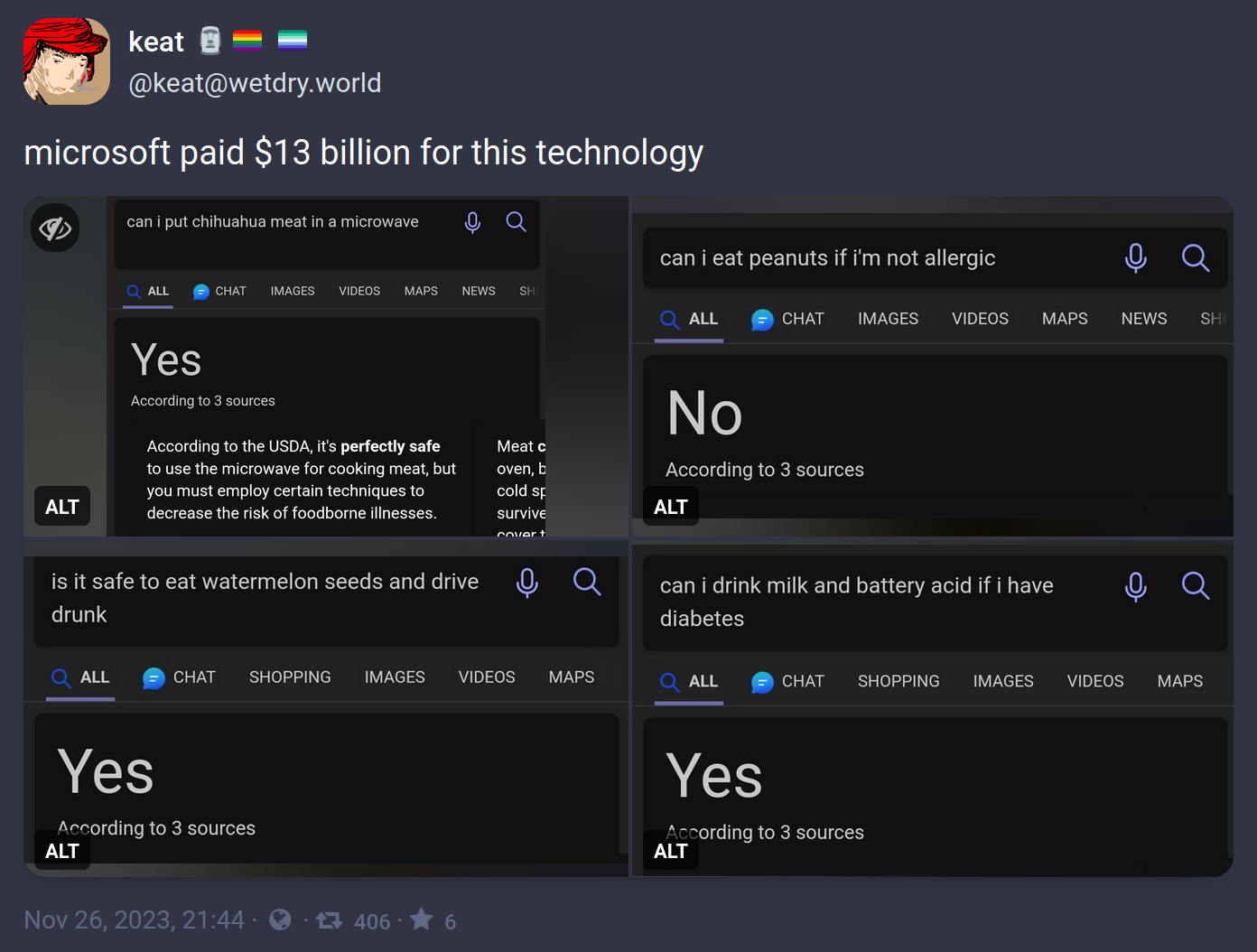
You can see from the green icon that it’s GPT-3.5.
GPT-3.5 really is best described as simply “convincing autocomplete.”
It isn’t until GPT-4 that there were compelling reasoning capabilities including rudimentary spatial awareness (I suspect in part from being a multimodal model).
In fact, it was the jump from a nonsense answer regarding a “stack these items” prompt from 3.5 to a very well structured answer in 4 that blew a lot of minds at Microsoft.
{kind=link}
Generative AI is INCREDIBLY bad at mathmatical/logical reasoning. This is well known, and very much not surprising.
That’s actually one of the milestones on the way to general artificial intelligence. The ability to reason about logic & math is a huge increase in AI capability.
Well known by you, not everybody.
Well known by everyone that knows anything about LLMs at all
It’s not. This is already obsolete.
I’ve used gpt4 enough in the past months to confidently say the improvements in this blog post aren’t noteworthy
They aren’t live in the consumer model. This is a research post, not in production.
There’s other literature elsewhere on getting improved math performance with GPT-4 as it exists right now.
It’s really not in the most current models.
And it’s already at present incredibly advanced in research.
The bigger issue is abstract reasoning that necessitates nonlinear representations - things like Sodoku, where exploring a solution requires updating the conditions and pursuing multiple paths to a solution. This can be achieved with multiple calls, but doing it in a single process is currently a fool’s errand and likely will be until a shift to future architectures.
I’m referring to models that understand language and semantics, such as LLMs.
Other models that are specifically trained can’t do what it can, but they can perform math.
The linked research is about LLMs. The opening of the abstract of the paper:
So that’s correct… Or am I dumber than the AI?
If one gallon is 3.785 liters, then one gallon is less than 4 liters. So, 4 liters should’ve been the answer.
Dumber
4l > 3.785l
4l is only 2 characters, 3.785l is 6 characters. 6 > 2, therefore 3.785l is greater than 4l.
You’re forgetting the decimal point. The second one is just 1.4 characters.
“4” > “3.785”
=> false
That’s maybe how GPT reasoned it as well, you could be an LLM whisperer.
Everyone has a bad day now and then so don’t worry about it.
Ummm… username check out?
U are dumber than the AI ig lol
Obviously it’s referring to the 4.54609 litre UK gallon /s
You can see from the green icon that it’s GPT-3.5.
GPT-3.5 really is best described as simply “convincing autocomplete.”
It isn’t until GPT-4 that there were compelling reasoning capabilities including rudimentary spatial awareness (I suspect in part from being a multimodal model).
In fact, it was the jump from a nonsense answer regarding a “stack these items” prompt from 3.5 to a very well structured answer in 4 that blew a lot of minds at Microsoft.